


The Trust Gap in Modern Data Systems
In multiple transformation initiatives, my teams successfully migrated large data ecosystems into scalable environments. Pipelines became faster, infrastructure more efficient, and compute more elastic.
However, decision-making slowed.
- Leaders questioned outputs
- Teams revalidated data repeatedly
- Insights required manual confirmation
This dynamic reflects a broader enterprise issue:
Data that is available is not always trusted.
This is what I refer to as the trust gap—a condition where systems function technically, but fail operationally in delivering confidence.
Most organizations respond by adding more:
- alerts
- monitoring dashboards
- thresholds
In my experience, this approach creates noise—not trust.
The missing piece is not more monitoring.
It is an operating model.
The Back‑of‑the‑House Data Reliability Operating Model
✅ Figure 1: Back‑of‑the‑House Data Reliability Operating Model
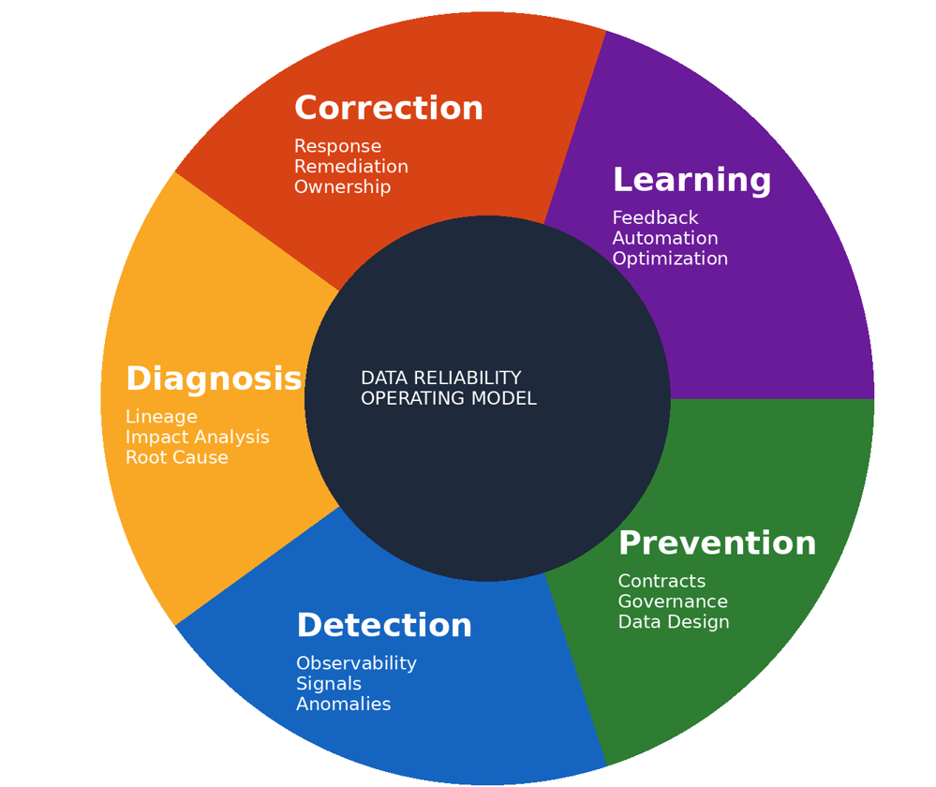
This model is built on five interconnected lifecycle stages:
1. Prevention
Reliability begins at ingestion—not after failure.
This involves:
- contract-driven data design
- schema validation
- ownership definition
The goal is to eliminate ambiguity before data enters the system.
2. Detection
Detection evolves from basic monitoring to behavioral intelligence.
Rather than asking: Did the pipeline fail?
We ask: Is the data behaving differently than expected?
This includes:
- anomaly detection
- freshness tracking
- volume and distribution monitoring
3. Diagnosis
Detection without context creates noise.
Diagnosis focuses on:
- lineage mapping
- dependency tracking
- impact analysis
The key shift here is moving from: “What broke?” → “Which decisions are affected?”
4. Correction
Reliability must be operationalized.
Correction introduces:
- structured incident response
- clearly defined ownership
- standardized remediation workflows
This elevates data issues to the same level as production incidents.
5. Learning
Learning converts reliability into a system.
Each incident feeds back into:
- improved detection models
- refined ingestion contracts
- stronger operational discipline
Over time, this creates a self-reinforcing system where reliability improves as complexity increases.
Extending the Model into Platform Architecture
While the Back‑of‑the‑House model defines the lifecycle, scaling it requires alignment with modern data and AI platforms.
✅ Figure 2: Enterprise Data Reliability Architecture
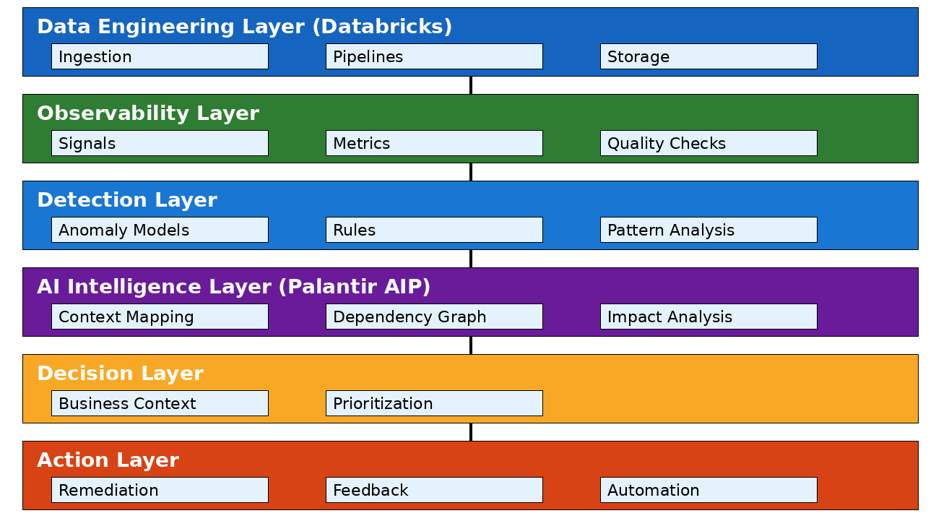
This architecture demonstrates how the model is operationalized across platforms:
Data Engineering Layer (Databricks)
Databricks provides:
- scalable ingestion
- distributed processing
- unified data pipelines
This is the foundation layer, ensuring data availability and consistency across domains.
Observability Layer
Captures:
- signals
- metrics
- data quality indicators
This provides real-time visibility into system health.
Detection Layer
Applies:
- statistical models
- rule-based validation
- pattern recognition
This is where data issues are identified before business impact.
AI Intelligence Layer (Palantir AIP)
This is the differentiating layer.
Palantir AIP enables:
- contextual interpretation
- dependency mapping
- impact-aware insights
It bridges the gap between data signals and business decisions.
Decision Layer
Aligns insights with:
- business priorities
- risk frameworks
- decision workflows
This ensures responses are proportional to impact.
Action Layer
Executes:
- remediation
- automation
- feedback loops
This closes the loop back into the operating model.
Why This Matters for AI
As organizations accelerate AI adoption, a critical constraint emerges:
Trust in data is not keeping pace with investment.
AI systems amplify:
- scale
- speed
- impact of errors
This means unreliable data no longer results in isolated issues—it results in:
- incorrect forecasts
- failed automation
- erosion of trust
The implication is clear:
👉 AI cannot scale without a reliable data operating model
Implications for Data Leaders
From my experience, data leaders must shift their focus in four ways:
1. From uptime → to decision confidence
Reliability is not about system completion—it is about trusted outcomes.
2. From monitoring → to operating models
Tools alone do not solve reliability. Structure does.
3. From pipelines → to systems thinking
Reliability spans ingestion, processing, decision, and action.
4. From reactive fixes → to continuous learning
Systems must improve with every failure.
Conclusion: Reliability Is a System You Build
The most important lesson from my work is this:
Reliability is not discovered—it is engineered.
It requires:
- lifecycle design
- platform integration
- continuous feedback
When implemented effectively, organizations move from asking:
“Is the data correct?”
To:
“Can we trust this decision?”
And that is the point where data becomes a true strategic asset.
Disclaimer
This article reflects the personal views and professional experiences of the author. It is based on original frameworks and methodologies developed through enterprise-scale data platform transformations. The perspectives shared do not represent any specific employer or affiliated organization. Any references to technologies or platforms are for illustrative purposes only and do not imply endorsement.
About DataIQ
DataIQ is where senior data and AI leaders from the world’s best-known organisations learn from trusted peers. Find out how to join.



